NLP: POS (Part of speech) Tagging & Chunking
POS tagging and chunking process in NLP using NLTK

Why do we need to learn POS Tagging?
In natural language, to understand the meaning of any sentence we need to understand the proper structure of the sentence and the relationship between the words available in the given sentence. In NLP, the most basic models are based on the Bag of Words (Bow) approach or technique but such models fail to capture the structure of the sentences and the syntactic relations between words.
To overcome this issue, we need to learn POS Tagging and Chunking in NLP.
Before getting into the deep discussion about the POS Tagging and Chunking, let us discuss the Part of speech in English language.
What is Part of speech?
In traditional grammar, a part of speech (POS) is a category of words that have similar grammatical properties. The part of speech explains how a word is used in a sentence. There are eight parts of speech in the English language: noun, pronoun, verb, adjective, adverb, preposition, conjunction, and interjection.
- Noun (N) — John, London, Table, Teacher, Pen, City, Happiness, Hope
- Pronoun(PRO) — I, We, They, You, He, She, It, Me, Us, Them, Him, Her, This, That
- Verb (V) — Read, Eat, Go, Speak, Run, Play, Live, Have, Like, Are, Is
- Adverb(ADV) — Slowly, Quietly, Very, Always, Never, Too, Well, Tomorrow
- Adjective(ADJ) — Big, Happy, Green, Young, Fun, Crazy, Three
- Preposition (P) — At, On, In, From, With, Near, Between, About, Under
- Conjunction (CON) — And, Or,But, Because, So, Yet, Unless, Since, If
- Interjection (INT) — Ouch! Wow! Great! Help! Oh! Hey! Hi!
The process of classifying words into their parts of speech and labeling them accordingly is known as part-of-speech tagging, POS-tagging, or simply tagging. Parts of speech are also known as word classes or lexical categories. The collection of tags used for a particular task is known as a tagset.
To understand the meaning of any sentence or to extract relationships and build a knowledge graph, POS Tagging is a very important step.
Universal Part-of-Speech Tagset:
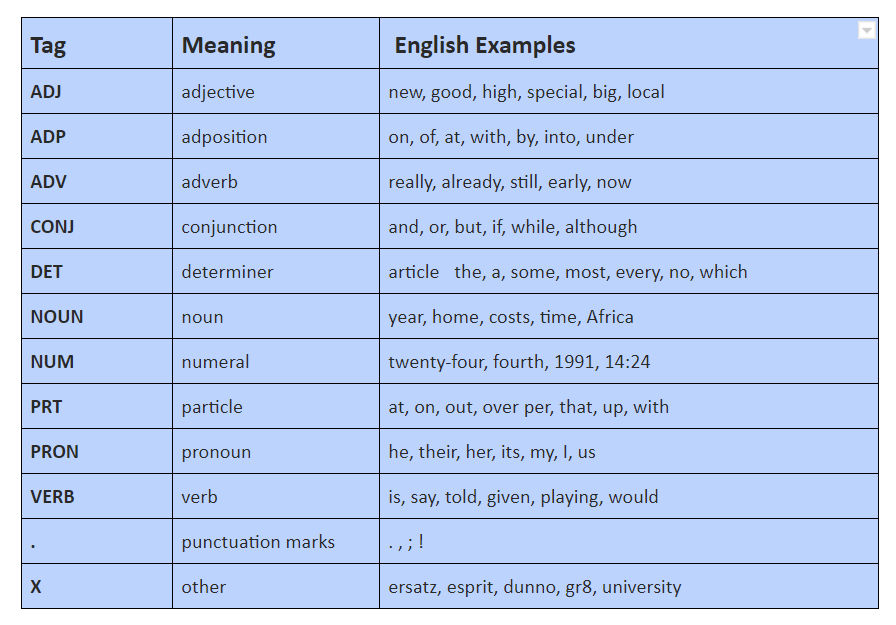
The Universal tagset of NLTK comprises 12 tag classes: Verb, Noun, Pronouns, Adjectives, Adverbs, Adpositions, Conjunctions, Determiners, Cardinal Numbers, Particles, Other/ Foreign words, Punctuations. This dataset has 3,914 tagged sentences and a vocabulary of 12,408 words.
POS tagging is a supervised learning solution which aims to assign parts of speech tag to each word of a given text (such as nouns, pronoun, verbs, adjectives, and others) based on its context and definition.
How does POS Tagging work?
As per the NLP Pipeline, we start POS Tagging with text normalization after obtaining a text from the source. Text normalization includes:
- Converting Text (all letters) into lower case
- Removing HTML tags
- Expanding contractions
- Converting numbers into words or removing numbers
- Removing special character (punctuations, accent marks and other diacritics)
- Removing white spaces
- Word Tokenization
- Stemming and Lemmatization
- Removing stop words, sparse terms, and particular words
We described text normalization steps in detail in our previous article (NLP Pipeline : Building an NLP Pipeline, Step-by-Step).
Once the given text is cleaned and tokenized then we apply pos tagger to tag tokenized words.
There are many tools containing POS taggers including NLTK, TextBlob, spaCy, Pattern, Stanford CoreNLP, Memory-Based Shallow Parser (MBSP), Apache OpenNLP, Apache Lucene, General Architecture for Text Engineering (GATE), FreeLing, Illinois Part of Speech Tagger, and DKPro Core.
POS Tagging using NLTK
The Different POS Tagging Techniques
There are different techniques for POS Tagging:
Lexical Based Methods — Assigns the POS tag the most frequently occurring with a word in the training corpus.
Rule-Based Methods — Assigns POS tags based on rules. For example, we can have a rule that says, words ending with “ed” or “ing” must be assigned to a verb. Rule-Based Techniques can be used along with Lexical Based approaches to allow POS Tagging of words that are not present in the training corpus but are there in the testing data.
Probabilistic Methods — This method assigns the POS tags based on the probability of a particular tag sequence occurring. Conditional Random Fields (CRFs) and Hidden Markov Models (HMMs) are probabilistic approaches to assign a POS Tag.
Deep Learning Methods — Recurrent Neural Networks can also be used for POS tagging.
Now we try to understand how POS tagging works using NLTK Library. NLTK has a function to assign pos tags and it works after the word tokenization.
What is Chunking (shallow parsing) ?
Before understanding chunking let us discuss what is chunk?
A chunk is a collection of basic familiar units that have been grouped together and stored in a person’s memory. In natural language, chunks are collective higher order units that have discrete grammatical meanings (noun groups or phrases, verb groups, etc.)
Chunking is a process of extracting phrases (chunks) from unstructured text. Instead of using a single word which may not represent the actual meaning of the text, it’s recommended to use chunk or phrase.
The basic technique we will use for entity detection is chunking, which segments and labels multi-token sequences as illustrated below:
Chunking tools: NLTK, TreeTagger chunker, Apache OpenNLP, General Architecture for Text Engineering (GATE), FreeLing.
There are a lot of libraries which give phrases out-of-box such as Spacy or TextBlob. NLTK just provides a mechanism using regular expressions to generate chunks.
Let us discuss a standard set of Chunk tags:
- Noun Phrase(NP)
- Verb Phrase (VP)
Noun Phrase: Noun phrase chunking, or NP-chunking, where we search for chunks corresponding to individual noun phrases.
In order to create an NP-chunk, we will first define a chunk grammar using POS tags, consisting of rules that indicate how sentences should be chunked. We will define this using a single regular expression rule.
In this case, we will define a simple grammar with a single regular-expression rule. This rule says that an NP chunk should be formed whenever the chunker finds an optional determiner (DT) followed by any number of adjectives (JJ) and then a noun (NN) then the Noun Phrase(NP) chunk should be formed.
The result is a tree, which we can either print or display graphically.
